I-EndpointSlice 분산 로직 분석
개요
엔포슬 분산을 보다가 궁금한 지점이 생겼다.

도대체 이 로직은 구체적으로 어떻게 동작하는 걸까?
1번에서 찾은 엔포슬들에 대해 바로 2번을 수행하나?
아니면 1번에서 리스트업을 한 후 다시 순회하며 2번을 하나?
코드 찾기
쿠버네티스는 모든 코어 로직을 한 레포지토리에서 관리하고 있다.[1]

엄밀하게는 여러 개의 분산 레포를 두고, 업데이트될 때 메인 레포로 전부 통합하는 방식이다.
여기에서 staging/src/k8s.io로 가보면 각종 코어 컴포넌트의 핵심이 되는 로직들을 찾을 수 있다.
쿠버네티스는 컨트롤러 관련 인터페이스를 노출해둔 뒤에 관련된 컨트롤러들을 만드는 방식이다.
근데 기본 컨트롤러들도 이런 식으로 한다는 것은 새롭게 알게 됐다.
그래서 엔드포인트 관련 코드도 하나의 디렉토리로 분리돼있다.
코드 세부 분석

조금 뒤져보니까 바로 코드를 찾을 수 있었다.[2]
주석만 봐도 알겠지만 방식은 후자이다.
- 존재하는 엔포슬 순회
- 더 이상 요구 상태와 다른 놈들을 지운다.
- 변화가 생긴 엔드포인트들을 갱신한다.
- 부모가 되는 서비스의 라벨을 잘 가지고 있는지, 아니라면 갱신하는 로직도 있다.
- 1에서 변화가 생긴 엔포슬에 대해 요구되는 엔드포인트들을 넣어준다.
- 2를 해도 요구되는 엔드포인트가 남았다면, 변화가 생기지 않은 슬라이스에 넣어주거나 새로운 슬라이스를 만든다.
나는 go 언어를 거의 완벽하게 모르는 입장이다만, 자바도 파이썬도 C도 다 다뤄본 입장에서 코드가 아예 감도 안 잡히는 것도 아니라 조금 더 코드를 보았다.
정말 잘 모르는 입장에서, 순수하게 보이는 대로, 내가 아는 만큼 해석을 해보려고 한다.
함수 선언부

함수 선언부 부분이다.
func 뒤에 괄호를 넣어서 함수를 메서드로서 기능하게 만들 수 있다.
그러니 이 함수는 사실 Reconciler라는 구조체?객체?의 메서드이다.
(C언어의 구조체에는 원래 메서드가 없어서 함수 포인터를 지정했던 것으로 기억하는데, 같은 방식이라 보면 되려나)
함수 이름 이후 괄호는 으레 그렇듯 매개변수를 나타낸다.
로거(logger)와 연관되는 서비스(service), 이에 엮이는 엔포슬 리스트(existingSlices), 희망되는 엔포슬 집합 상태(desiredSet), 메타데이터(endpointMeta)를 담는 듯하다.
여기에 desiredSet은 나중에 보니 알겠는데, 현재 서비스에 대해서 요구되는 모든 엔드포인트 값의 집합인가보다.
그 다음 괄호에는 리턴 타입이 담긴다.
세 개의 엔포슬 리스트와 2개의 int 값이 반환된다.
첫번째 로직
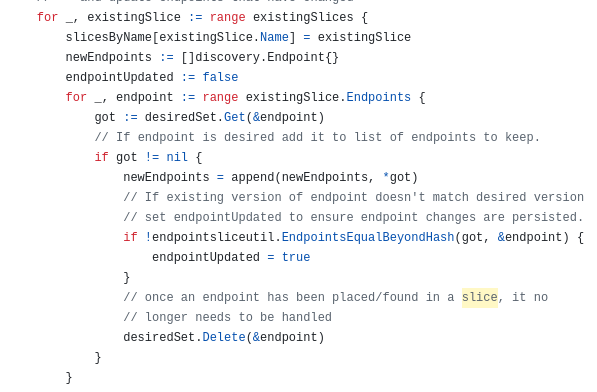
일단 현존하는 슬라이스를 순회하는 게 하나의 큰 블록이다.
각 슬라이스를 또 순회하며, 내부의 엔드포인트가 요구된 엔드포인트인지 아닌지 체크한다.
아니라면 nil이 got 변수에 담기는데 이러면 그냥 넘어가게 돼있다.
요구된 엔포라면 일단 새로운 엔드포인트 리스트(구체적으로 슬라이스)에 넣는다.
슬라이스란 건 동적 크기 배열이다.
[]int{}라고 하면 int 담는 빈 슬라이스를 만드는 것이다.
내부적으로는 배열의 메모리 주소를 사용한다고 한다.
여기에 값을 추가할 때는 append({슬라이스 이름}, {값})과 같은 방식이라고..
그리고 버전 체크를 해주며 변경될 놈인지 체크한다.
이미 조회된 엔포라면 요구 집합에서 삭제한다.
(Set이란 거 보니 어차피 해시 테이블인데 왜 지울까? 크기 이슈?)

다음 코드는 이러하다.
라벨 관련 업데이트를 진행한다.
내부 코드를 봤는데, 별 것 없이 말 그대로 그냥 서비스 기준으로 라벨을 반환한다.
엔드포인트 업데이트 플래그가 걸렸거나, newEndpoints 슬라이스의 길이가 해당 엔포슬 길이와 맞지 않는다면?
길이가 맞지 않는다는 건 위에서 got이 nil된 상황이 있었다는 것이고, 즉 없어져야 할 엔드포인트가 있었다는 것.
업데이트 플래그가 걸렸으면 그냥 업데이트해야 할 엔드포인트라는 것..
그래서 제거된 개수를 세거나, 엔포슬을 지울 수 있게 지울 리스트에 넣거나, 업데이트될 리스트에 넣어준다.
한 줄 짜리 코드에 의해 라벨만 업데이트돼야 하는 상황일 수도 있는데, 이때에 대해서도 조건이 걸려있다.
이런 사항들이 없다면 해당 엔포슬은 바뀌지 않을 것이며 또 이것 역시 리스트로 관리한다.
마지막에서 추가될 개수를 Set의 길이로 구한다.
그래서 위에서 Set을 매번 제거해준 것이다.
두번째 로직

아직도 desiredSet이 비지 않았다면, 새롭게 추가된 엔드포인트가 있다는 뜻이다.
해당 엔포들을 업데이트될 엔포슬에 넣는 작업을 한다.
slices라는 변수에 넣는 과정이 있는데, 최대한 가득 찬 엔포슬부터 채우기 위한 것 같다..
그래서 desiredSet에서 아무거나 빼서 엔드포인트를 추가하는 작업을 해준다.
굳이 채워진 놈부터 더 채우는 이유는 아마 엔포슬 개수를 최대한 적게 유지하기 위함일 것이라 생각한다.
세번째 로직

이제는 새로 엔포슬을 만들 준비도 하면서 마지막 순회를 한다.
2번 로직을 거쳤음에도 처리할 엔드포인트가 남은 상태일 때 한무 로직을 돈다.
일단 채우고자 하는 엔포슬을 찾는다.
getSliceToFill 함수는 현재 남은 엔드포인트를 싹 처리할 수 있는 최적의 엔포슬을 찾는 함수였다.
가능하면 한 공간도 남지 않고 딱 맞게 엔드포인트를 채울 수 있는 엔포슬이 베스트이다.
그런 게 없다면 그나마 남는 자리가 적은 엔포슬이 채택된다.
남은 엔포들을 처리할 엔포슬이 없는 상황이면, nil을 반환한다!
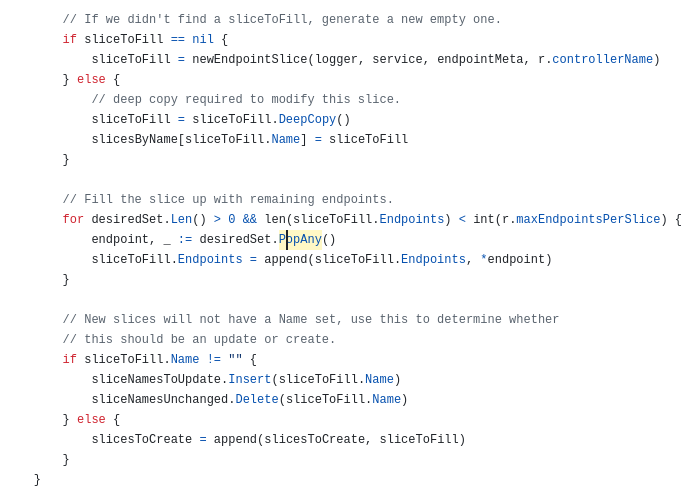
거의 다 왔다.
위에서 nil이 반환됐으면 새로운 엔포슬을 만든다.
그 다음에 선택된 엔포슬을 순회하며 또 열심히 엔드포인트를 최대한 우겨넣는다.
만약 새로 만들어진 엔포슬이었다면 만들어져야 하는 리스트쪽에 넣어주고, 아니라면 업데이트된다는 리스트에 넣어준다.

궁금점
왜 굳이 업데이트된 놈에 먼저 새로운 엔드포인트를 넣는가?
많은 엔포슬을 업데이트할수록 많은 오버헤드가 발생하나?
사실 단순하게 생각만 해도 해당 정보들이 전부 etcd에 담길 텐데 많은 오브젝트가 변동될 수록 안 좋을 것 같기도 하다.
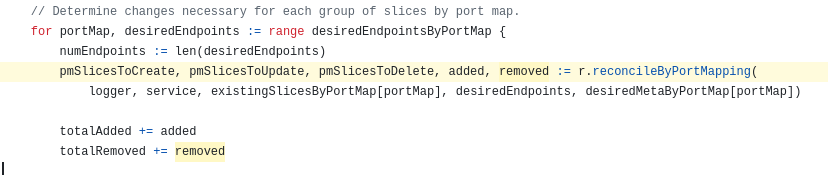
내가 보던 함수는 addressType으로 엔포슬을 구분하는 상위 함수에서 사용된다.
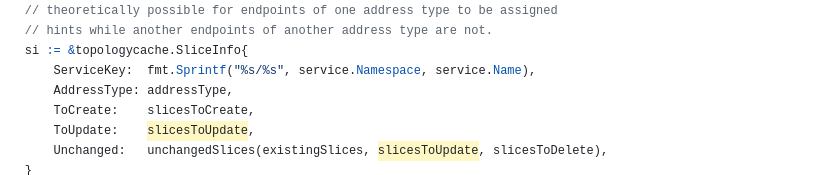
여기에서도 열심히 업데이트할 모든 엔포슬을 묶어댄다.

이 함수의 반환은 에러들이므로, 여기 어디에선가 업데이트와 관련된 로직이 발생한다고 추측해볼 수 있다.
음.. finalize가 Finalizer랑 관련되는 건가 무심코 넘어갔다가 시간을 조금 들이게 됐다.

여기에서 모든 작업이 일어나기 시작한다.
당연하지만, kube-apiserver에 각 엔포슬을 업데이트해달라고 찡찡댄다.

Go 클라이언트 라이브러리가 어떻게 생겼는지는 잘 몰라도 결국 이 api를 호출하게 된다는 말이다.
여기에서 더 파고들 수는 있지만, 이쯤 해도 충분히 납득이 가긴 한다.
결국 엔포슬이 업데이트되는 만큼 api 서버로 요청이 날아가게 된다.
그러니 이 요청 수를 줄이려면, 업데이트되는 개수를 줄이는 수밖에 없다.
3번 로직에서, 남은 엔드포인트들은 현재의 엔포슬들에 최대한 분산해서 담아도 되지 않나?
가령 현재 엔포슬 당 엔드포인트를 담는 최대값이 100이라 쳐보자.
남은 엔드포인트는 50개이고, 현재 엔포슬은 3개로 60, 50, 40개를 담고 있다.
이 경우 50개를 담은 엔포슬이 채택된다.
그럼 현재 엔포슬이 80, 80, 90이라면?
이 경우 새로운 엔포슬이 만들어지게 된다.
이게 효율적인가?
사실 위의 의문을 탐구하면서 어느 정도 해소됐다.
api 요청은 하나의 엔포슬당 이뤄지기 때문에 가급적이면 적게 변경을 만들어내는 것이 이득이라 그렇다.
결론
대체 라이브러리가 아닌 독립적인 프로세스로 돌아가는, 컨테이너로서 메인 프로세스를 담당하는 메인 코드가 어딨나 한참 헤맸다.
보니까 cmd라는 디렉토리에 main.go가 아닌, 이러한 이름으로 지정돼있었다.[3]

name이란 디렉에 기본으로 사용되는 무수한 컨트롤러 목록을 확인할 수 있다.
이 name들은 app 디렉토리 안 속에 api 유형으로 묶인 각 파일에서 사용된다.
그럼 해당 파일들은 또 pkg/controller의 디렉토리에 있는 컨트롤러 바이너리를 가져오고..
이 놈들이 핵심 로직을 함께 불러와서 실행하는..
그리고 그 파일들은 controllermanager.go를 통해 등록되고, 여기에서 실행할 때 주는 각종 플래그값까지 읽어서 결과적으로 kube-controller-manager가 실행된다.
코드로만 분석하려다보니 거시적인 작동 구조는 헷갈린다..
사두용미 느낌이 나는 분석이었달까..
새로운 사실들을 알게 됐다.
- 쿠버네티스가 기본 컨트롤러를 올리는 방식
- 엔포슬이 엔드포인트를 갱신하거나 추가하는 로직
- 짤막 고언어 문법..
정말 엄밀한 수준으로 분석을 하려면 고언어를 익혀야 할 것 같고, 시간도 많이 걸릴 것이라 생각해서 여기에서 일단 마치도록 한다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| EndpointSlice | knowledge | 2025-02-16 |
| I-EndpointSlice 분산 로직 분석 | topic/idea | 2025-01-03 |